Pkg.installed("OpenCL") || Pkg.add("OpenCL")
Pkg.installed("CLFFT") || Pkg.add("CLFFT")
Pkg.installed("BenchmarkTools") || Pkg.add("BenchmarkTools")
# Some misc packages we are going to use
using BenchmarkTools
The JuliaGPU Ecosystem¶
by: Valentin Churavy (Github and Twitter: @vchuravy)
What are we going to talk about?¶
- Why are we interested in GPUs
- How can we work with GPUs in Julia
- Working with the APIs
- FFT and BLAS
- GPUArrays.jl (by Simon Danish)
- CUDAnative.jl (by Tim Maleadt)
Why are we interested in GPUs¶
A GPU is a Graphics Processing Unit they were initially developed to accelerating rendering of graphically intensive appliacations (e.g games and CAD). They are massively parallel computing devices and they sit in everyones computers. Sold by Intel, Nvidia, and AMD. There architecture is optimised to perfome pipelined per-pixel operations in a SIMD model.
- Available in many desktops and HPC environments
- Highly performant for certain tasks
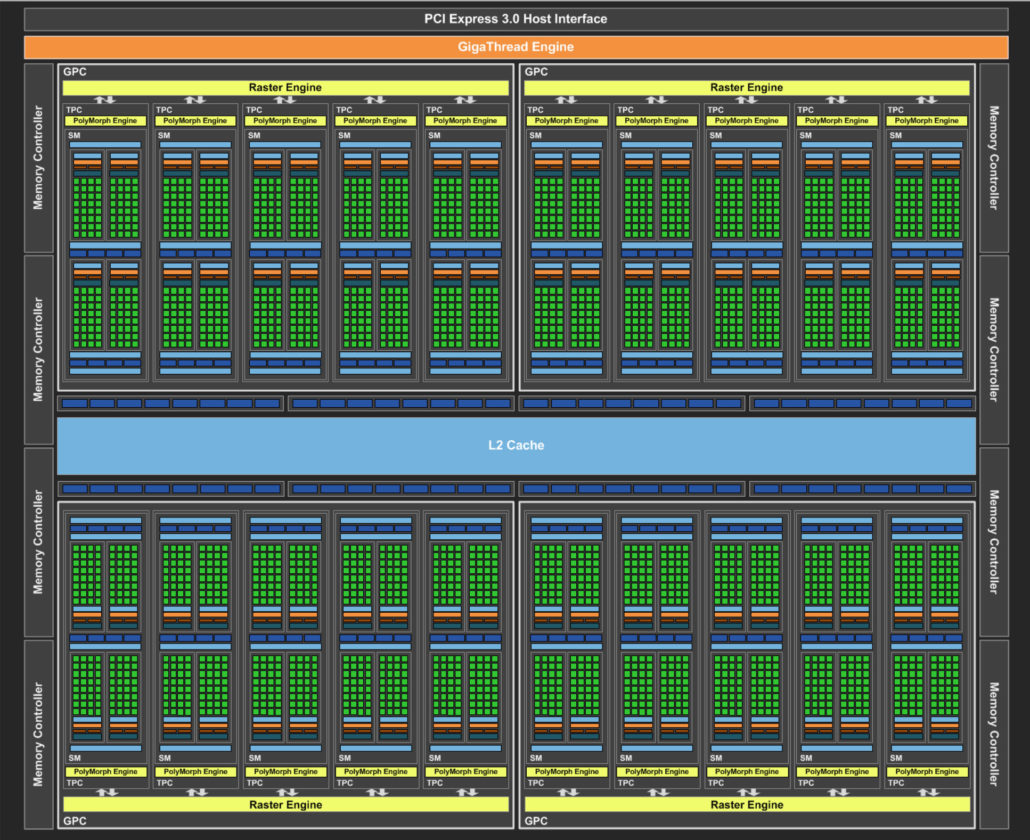
- Green: CUDA cores
- Blue: Memory
GPGPU¶
There exists speciailised programming languages to program GPUs. For graphics we call these programs shaders and for general purpose programs we call them kernels.
- 2003 Brook to translate C-like code into a shader language
- 2006 Initial release of CUDA
- 2009 Initial release of OpenCL
What are GPUs good for¶
- Image processing
- Convolutional Deep Learning
- Matrix operations
- FFT
- ...
The other side of the coins¶
- Memory transfer cost
- Program needs to fit programming model
- There are no magic speedups
- Memory is limited
- SIMD programming model --> warp divergence
How can we work with GPUs in Julia?¶
Access to the APIs¶
There are two major APIs to access device resources and start kernels. The open standard OpenCL and Nvidia's CUDA. In Julia we support both APIs through packages in the JuliaGPU organisation.
- OpenCL.jl https://github.com/JuliaGPU/OpenCL.jl
- CUDAdrv.jl https://github.com/JuliaGPU/CUDAdrv.jl
- CUDArt.jl https://github.com/JuliaGPU/CUDArt.jl
I am going to use primarily OpenCL in this notebook, since OpenCL can also run on CPUs.
OpenCL Example I¶
using OpenCL
device, ctx, queue = cl.create_compute_context();
We will need to define a OpenCL C kernel to execute on the compute device.
kernel = """
__kernel void sum(__global const float *a,
__global const float *b,
__global float *c)
{
int gid = get_global_id(0);
c[gid] = a[gid] + b[gid];
}
""";
p = cl.Program(ctx, source=kernel) |> cl.build!
k = cl.Kernel(p, "sum")
OpenCL Example II¶
N = 500_000
a = rand(Float32, N);
b = rand(Float32, N);
c = zeros(Float32, N);
# Move data to device
a_buff = cl.Buffer(Float32, ctx, (:r, :copy), hostbuf=a)
b_buff = cl.Buffer(Float32, ctx, (:r, :copy), hostbuf=b)
c_buff = cl.Buffer(Float32, ctx, :w, length(a))
# execute kernel
queue(k, size(a), nothing, a_buff, b_buff, c_buff)
r = cl.read(queue, c_buff);
norm(r - (a+b)) ≈ zero(Float32)
Benchmarking¶
Most GPU code is executed asynchronously so benchmarking takes a bit of care. If you see benchmarks make sure that the account for overhead (copying data back and forth and actually running the code.) OpenCL.jl currently blocks on many high-level operations.
@benchmark begin
evt = queue($k, size(a), nothing, $a_buff, $b_buff, $c_buff)
end
@benchmark broadcast!(+, $c, $a, $b)
If you don't already have code in CUDA C or OpenCL C you probably don't need to/want to use these APIs directly.
BLAS and FFT¶
There are libraries available for BLAS and FFT based upon CUFFT, CUBLAS, CLFFT, CLBLAS at https://github.com/JuliaGPU these libraries have varying level of support.
Let's calculate an FFT!
import CLFFT
const clfft = CLFFT;
N = 100
X = ones(Complex64, N)
bufX = cl.Buffer(Complex64, ctx, :copy, hostbuf=X)
p = clfft.Plan(Complex64, ctx, size(X))
clfft.set_layout!(p, :interleaved, :interleaved)
clfft.set_result!(p, :inplace)
clfft.bake!(p, queue)
clfft.enqueue_transform(p, :forward, [queue], bufX, nothing)
result = cl.read(queue, bufX)
@assert isapprox(norm(result - fft(X)), zero(Float32))
Thanks to all the JuliaGPU contributors:¶
(in no particular order)
- @maleadt
- @SimonDanisch
- @jakebolewski
- @kshyatt
- @dfdx
- @timholy
- @ranjan
- @denizyuret
- @ekobir
- @lindahua
- @grollinger
Upcoming GPUArrays.jl!¶
GPUArrays.jl solves the problem that depending on your GPU you might want to use different libraries and abstracts away some of the complexity.